Python 环境加载中…
线程与进程
本章为概念阅读 · 预计 15 分钟
教学 01 / 04· 已读
前言
学编程,谁没有为线程折腾过啊。
这一章是纯阅读章节,没有练习题。
因为浏览器里的 Pyodide 环境不支持真正的多线程和多进程(
threading、multiprocessing在 Web Worker 里跑不起来),所以这一章我们只讲概念、看代码示例,不在网页里跑。各位想动手验证的话,把示例代码贴到本地 Python 环境里跑一下就能看到效果。
这一章要讲的内容
整章按三大块展开:
线程和进程
│
├── 线程与进程(基础概念)
│
├── 多线程编程
│ ├── 线程的创建
│ ├── 线程合并(join 方法)
│ ├── 线程同步与互斥锁
│ ├── Condition 条件变量
│ ├── 线程间通信
│ └── 后台线程
│
└── 进程
├── 类 Process
├── 把进程创建成类
├── daemon 属性
├── join 方法
├── Pool
└── 进程间通信
教学 02 / 04· 已读
线程与进程
线程与进程是操作系统里面的术语,简单来讲,每一个应用程序都有一个自己的进程。
操作系统会为这些进程分配一些执行资源,例如内存空间等。
在进程中,又可以创建一些线程,他们共享这些内存空间,并由操作系统调用,以便并行计算。
我们都知道现代操作系统比如 Mac OS X、UNIX、Linux、Windows 等可以同时运行多个任务。
打个比方,你一边在用浏览器上网,一边在听音乐,一边用 Markdown 写博客,这就是多任务,至少同时有 3 个任务正在运行。
当然还有很多任务悄悄地在后台同时运行着,只是桌面上没有显示而已。
进程
对于操作系统来说,一个任务就是一个进程(Process),比如打开一个浏览器就是启动一个浏览器进程,打开 PyCharm 就是启动了一个 PyCharm 进程,打开 Markdown 就是启动了一个 Md 的进程。
虽然现在多核 CPU 已经非常普及了。
可是由于 CPU 执行代码都是顺序执行的,这时候我们就会有疑问,单核 CPU 是怎么执行多任务的呢?
其实就是操作系统轮流让各个任务交替执行:任务 1 执行 0.01 秒,切换到任务 2,任务 2 执行 0.01 秒,再切换到任务 3,执行 0.01 秒……这样反复执行下去。
表面上看,每个任务都是交替执行的,但是由于 CPU 的执行速度实在太快,我们肉眼和感觉上没法识别出来,就像所有任务都在同时执行一样。
真正的并行执行多任务只能在多核 CPU 上实现,但是由于任务数量远远多于 CPU 的核心数量,所以操作系统也会自动把很多任务轮流调度到每个核心上执行。
线程
有些进程不仅仅只是干一件事,比如浏览器,可以播放视频、播放音频、看文章、编辑文章等等,其实这些都是浏览器进程中的子任务。在一个进程内部,要同时干多件事,就需要同时运行多个「子任务」,我们把进程内的这些「子任务」称为线程(Thread)。
由于每个进程至少要干一件事,所以一个进程至少有一个线程。
当然,一个进程也可以有多个线程,多个线程可以同时执行,多线程的执行方式和多进程是一样的,也是由操作系统在多个线程之间快速切换,让每个线程都短暂地交替运行,看起来就像同时执行一样。
Python 的多任务方案
那么在 Python 中我们要同时执行多个任务怎么办?
有两种解决方案:
一种是启动多个进程,每个进程虽然只有一个线程,但多个进程可以一块执行多个任务。
还有一种方法是启动一个进程,在一个进程内启动多个线程,这样多个线程也可以一块执行多个任务。
当然还有第三种方法,就是启动多个进程,每个进程再启动多个线程,这样同时执行的任务就更多了。当然这种模型更复杂,实际很少采用。
总结一下,多任务的实现有 3 种方式:
- 多进程模式
- 多线程模式
- 多进程 + 多线程模式
同时执行多个任务通常各个任务之间并不是没有关联的,而是需要相互通信和协调。有时任务 1 必须暂停等待任务 2 完成后才能继续执行,有时任务 3 和任务 4 又不能同时执行,所以多进程和多线程的程序的复杂度要远远高于单进程单线程的程序。
因为复杂度高,调试困难,所以不是迫不得已,我们也不想编写多任务。
但是有很多时候,没有多任务还真不行。想想在电脑上看电影,就必须由一个线程播放视频,另一个线程播放音频,否则单线程实现的话就只能先把视频播放完再播放音频,或者先把音频播放完再播放视频,这显然是不行的。
教学 03 / 04· 已读
多线程编程
线程并不是始终保持一个状态的,其状态大概如下:
- New:创建
- Runnable:就绪,等待调度
- Running:运行
- Blocked:阻塞,可能在 Wait、Locked、Sleeping
- Dead:消亡
线程也有不同的类型,大致可分为:
- 主线程
- 子线程
- 守护线程(后台线程)
- 前台线程
1、线程的创建
Python 提供两个模块进行多线程的操作,分别是 thread 和 threading。
前者是比较低级的模块,用于更底层的操作,一般应用级别的开发不常用。
我们使用 threading 来举个例子:
python
import time
import threading
class MyThread(threading.Thread):
def run(self):
for i in range(5):
print(f'thread {self.name}, @number: {i}')
time.sleep(1)
def main():
print("Start main threading")
# 创建三个线程
threads = [MyThread() for i in range(3)]
# 启动三个线程
for t in threads:
t.start()
print("End Main threading")
if __name__ == '__main__':
main()运行结果(不同环境输出可能不一样):
Start main threading
thread Thread-1, @number: 0
thread Thread-2, @number: 0
thread Thread-3, @number: 0
End Main threading
thread Thread-2, @number: 1
thread Thread-1, @number: 1
thread Thread-3, @number: 1
...
2、线程合并(join 方法)
上面的示例打印结果显示,主线程结束后子线程还在运行。如果需要主线程等待子线程运行完后再退出,要怎么办呢?
这时候就需要用到 join 方法了。在上面的例子里新增一段代码:
python
import time
import threading
class MyThread(threading.Thread):
def run(self):
for i in range(5):
print(f'thread {self.name}, @number: {i}')
time.sleep(1)
def main():
print("Start main threading")
threads = [MyThread() for i in range(3)]
for t in threads:
t.start()
# 依次让新创建的线程执行 join
for t in threads:
t.join()
print("End Main threading")
if __name__ == '__main__':
main()打印结果中,主线程是在等待子线程运行结束后才结束的。
3、线程同步与互斥锁
使用线程加载获取数据时,通常会造成数据不同步的情况。这时候我们可以给资源进行加锁,访问资源的线程需要获得锁才能访问。
threading 模块提供了一个 Lock 功能:
python
lock = threading.Lock()在线程中获取锁:
python
lock.acquire()使用完成后,需要释放锁:
python
lock.release()为了支持在同一线程中多次请求同一资源,Python 还提供了可重入锁(RLock)。RLock 内部维护着一个 Lock 和一个 counter 变量,counter 记录了 acquire 的次数,使得资源可以被多次 acquire。直到一个线程所有的 acquire 都被 release,其他线程才能获得资源。
python
r_lock = threading.RLock()4、Condition 条件变量
使用锁可以达到线程同步,但是在更复杂的环境,需要针对锁进行一些条件判断。Python 提供了 Condition 对象。
使用 Condition 对象可以在某些事件触发或者达到特定的条件后才处理数据。Condition 除了具有 Lock 对象的 acquire 方法和 release 方法外,还提供了 wait 和 notify 方法。
线程首先 acquire 一个条件变量锁。如果条件不足,则该线程 wait;如果满足就执行线程,甚至可以 notify 其他线程。其他处于 wait 状态的线程接到通知后会重新判断条件。
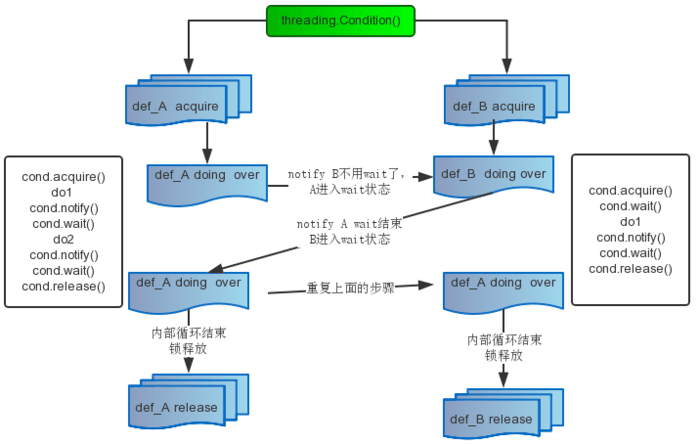
该模式常用于生产者消费者模式,下面是在线购物买家和卖家的示例:
python
import threading
import time
class Consumer(threading.Thread):
def __init__(self, cond, name):
super(Consumer, self).__init__()
self.cond = cond
self.name = name
def run(self):
# 确保先运行 Producer 中的方法
time.sleep(1)
self.cond.acquire()
print(self.name + ': 我这两件商品一起买,可以便宜点吗')
self.cond.notify()
self.cond.wait()
print(self.name + ': 我已经提交订单了,你修改下价格')
self.cond.notify()
self.cond.wait()
print(self.name + ': 收到,我支付成功了')
self.cond.notify()
self.cond.release()
print(self.name + ': 等待收货')
class Producer(threading.Thread):
def __init__(self, cond, name):
super(Producer, self).__init__()
self.cond = cond
self.name = name
def run(self):
self.cond.acquire()
# 释放对锁的占用,同时线程挂起在这里,直到被 notify 并重新占有锁
self.cond.wait()
print(self.name + ': 可以的,你提交订单吧')
self.cond.notify()
self.cond.wait()
print(self.name + ': 好了,已经修改了')
self.cond.notify()
self.cond.wait()
print(self.name + ': 嗯,收款成功,马上给你发货')
self.cond.release()
print(self.name + ': 发货商品')
cond = threading.Condition()
consumer = Consumer(cond, '买家(两点水)')
producer = Producer(cond, '卖家(三点水)')
consumer.start()
producer.start()5、线程间通信
如果程序中有多个线程,这些线程避免不了需要相互通信。从一个线程向另一个线程发送数据最安全的方式是使用 queue 库中的队列。创建一个被多个线程共享的 Queue 对象,这些线程通过使用 put() 和 get() 操作来向队列中添加或者删除元素。
python
from queue import Queue
from threading import Thread
isRead = True
def write(q):
# 写数据进程
for value in ['两点水', '三点水', '四点水']:
print(f'写进 Queue 的值为:{value}')
q.put(value)
def read(q):
# 读取数据进程
while isRead:
value = q.get(True)
print(f'从 Queue 读取的值为:{value}')
if __name__ == '__main__':
q = Queue()
t1 = Thread(target=write, args=(q,))
t2 = Thread(target=read, args=(q,))
t1.start()
t2.start()Python 还提供了 Event 对象用于线程间通信,它是由线程设置的信号标志。如果信号标志为真,则其他线程等待直到信号清除。
Event 对象的常用方法:
set():把内部信号标志设为真clear():把内部信号标志清除(设为假)isSet():查询当前信号标志状态wait():当信号为真时立刻返回;为假时阻塞,直到信号变真
python
import threading
class mThread(threading.Thread):
def __init__(self, threadname):
threading.Thread.__init__(self, name=threadname)
def run(self):
global event
if event.isSet():
event.clear()
event.wait()
print(self.getName())
else:
print(self.getName())
event.set()
event = threading.Event()
event.set()
t1 = []
for i in range(10):
t = mThread(str(i))
t1.append(t)
for i in t1:
i.start()6、后台线程
默认情况下,主线程退出之后,即使子线程没有 join,主线程结束后子线程也依然会继续执行。如果希望主线程退出后,其子线程也退出而不再执行,则需要把子线程设置为后台线程。Python 提供了 setDaemon 方法(或者直接给线程的 daemon 属性赋 True)。
教学 04 / 04
进程
Python 中的多线程其实并不是真正的多线程(受 GIL 限制),如果想要充分使用多核 CPU 的资源,在 Python 中大部分情况需要使用多进程。
Python 提供了非常好用的多进程包 multiprocessing,只需要定义一个函数,Python 会完成其他所有事情。
借助这个包,可以轻松完成从单进程到并发执行的转换。multiprocessing 支持子进程、通信和共享数据、执行不同形式的同步,提供了 Process、Queue、Pipe、Lock 等组件。
1、类 Process
创建进程的类:Process([group [, target [, name [, args [, kwargs]]]]])
target:表示调用对象args:表示调用对象的位置参数元组kwargs:表示调用对象的字典name:为别名group:实质上不使用
下面是一个创建函数并将其作为多个进程的例子:
python
import multiprocessing
import time
def worker(interval, name):
print(name + '【start】')
time.sleep(interval)
print(name + '【end】')
if __name__ == "__main__":
p1 = multiprocessing.Process(target=worker, args=(2, '两点水1'))
p2 = multiprocessing.Process(target=worker, args=(3, '两点水2'))
p3 = multiprocessing.Process(target=worker, args=(4, '两点水3'))
p1.start()
p2.start()
p3.start()
print("The number of CPU is:" + str(multiprocessing.cpu_count()))
for p in multiprocessing.active_children():
print("child p.name:" + p.name + "\tp.id" + str(p.pid))
print("END!!!!!!!!!!!!!!!!!")2、把进程创建成类
也可以把进程创建成一个类,当进程 p 调用 start() 时,自动调用 run() 方法:
python
import multiprocessing
import time
class ClockProcess(multiprocessing.Process):
def __init__(self, interval):
multiprocessing.Process.__init__(self)
self.interval = interval
def run(self):
n = 5
while n > 0:
print(f"当前时间: {time.ctime()}")
time.sleep(self.interval)
n -= 1
if __name__ == '__main__':
p = ClockProcess(3)
p.start()3、daemon 属性
daemon 属性的作用,看下下面两个例子的对比:
没有加 daemon 属性的例子:
python
import multiprocessing
import time
def worker(interval):
print(f'工作开始时间:{time.ctime()}')
time.sleep(interval)
print(f'工作结束时间:{time.ctime()}')
if __name__ == '__main__':
p = multiprocessing.Process(target=worker, args=(3,))
p.start()
print('【END】')输出:
【END】
工作开始时间:Mon Oct 9 17:47:06 2017
工作结束时间:Mon Oct 9 17:47:09 2017
进程 p 添加 daemon 属性之后:
python
import multiprocessing
import time
def worker(interval):
print(f'工作开始时间:{time.ctime()}')
time.sleep(interval)
print(f'工作结束时间:{time.ctime()}')
if __name__ == '__main__':
p = multiprocessing.Process(target=worker, args=(3,))
p.daemon = True
p.start()
print('【END】')输出只有:
【END】
可见,如果在子进程中添加了 daemon 属性,主进程结束的时候子进程也会跟着结束,所以没有打印子进程的信息。
4、join 方法
如果想要让子进程执行完该怎么做?可以用 join 方法。join 方法的主要作用是:阻塞当前进程,直到调用 join 方法的那个进程执行完,再继续执行当前进程。
python
import multiprocessing
import time
def worker(interval):
print(f'工作开始时间:{time.ctime()}')
time.sleep(interval)
print(f'工作结束时间:{time.ctime()}')
if __name__ == '__main__':
p = multiprocessing.Process(target=worker, args=(3,))
p.daemon = True
p.start()
p.join()
print('【END】')5、Pool
如果需要很多子进程,难道我们要一个一个地去创建吗?
当然不用,可以使用进程池批量创建子进程:
python
from multiprocessing import Pool
import os
import time
import random
def long_time_task(name):
print(f'进程的名称:{name} ;进程的 PID: {os.getpid()} ')
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print(f'进程 {name} 运行了 {end - start} 秒')
if __name__ == '__main__':
print(f'主进程的 PID:{os.getpid()}')
p = Pool(4)
for i in range(6):
p.apply_async(long_time_task, args=(i,))
p.close()
# 等待所有子进程结束后再关闭主进程
p.join()
print('【End】')注意:Pool 对象调用 join() 方法会等待所有子进程执行完毕,调用 join() 之前必须先调用 close(),调用 close() 之后就不能继续添加新的 Process 了。
请注意输出结果,子进程 0、1、2、3 是立刻执行的,而子进程 4 要等待前面某个子进程完成后才执行。这是因为 Pool(4) 限制最多同时执行 4 个进程。如果改成:
python
p = Pool(5)就可以同时跑 5 个进程了。
6、进程间通信
进程之间肯定是需要通信的,操作系统提供了很多机制来实现进程间通信。Python 的 multiprocessing 模块包装了底层的机制,提供了 Queue、Pipes 等多种方式来交换数据。
以 Queue 为例,在父进程中创建两个子进程,一个往 Queue 里写数据,一个从 Queue 里读数据:
python
from multiprocessing import Process, Queue
import os
import time
import random
def write(q):
print(f'写进程的 PID: {os.getpid()}')
for value in ['两点水', '三点水', '四点水']:
print(f'写进 Queue 的值为:{value}')
q.put(value)
time.sleep(random.random())
def read(q):
print(f'读进程的 PID: {os.getpid()}')
while True:
value = q.get(True)
print(f'从 Queue 读取的值为:{value}')
if __name__ == '__main__':
# 父进程创建 Queue,并传给各个子进程
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
pw.start()
pr.start()
pw.join()
# pr 进程里是死循环,无法等待其结束,只能强行终止
pr.terminate()输出:
读进程的 PID: 13208
写进程的 PID: 10864
写进 Queue 的值为:两点水
从 Queue 读取的值为:两点水
写进 Queue 的值为:三点水
从 Queue 读取的值为:三点水
写进 Queue 的值为:四点水
从 Queue 读取的值为:四点水
到这里,多线程和多进程的核心 API 就讲完了。各位想动手验证的话,把代码贴到本地 Python 环境(不是浏览器 Pyodide)里就能跑起来。